
科技改變生活 · 科技引領未來
科技改變生活 · 科技引領未來

作者|Walker信息技術的發展不斷推動著互聯網技術的變革,Web技術作為互聯網時的標志性技術,正處于這場技術變的核心。從網頁的鏈接到數據的鏈接,Web技術正在逐步朝向Web之父Berners-Lee設想中的語義網絡演變。語義網絡是一張數據
作者 | Walker
信息技術的發展不斷推動著互聯網技術的變革,Web技術作為互聯網時的標志性技術,正處于這場技術變的核心。從網頁的鏈接到數據的鏈接,Web技術正在逐步朝向Web之父Berners-Lee設想中的語義網絡演變。語義網絡是一張數據構成的網絡,語義網絡技術向用戶提供的是一個查詢環境,其核心要義是以圖形的方式向用戶返回經過加工和推理的知識。而知識圖譜技術則是實現智能化語義檢索的基礎和橋梁。
一、知識圖譜的定義、結構與知識庫
知識圖譜的概念是由谷歌公司在2012年5月17日提出的, 谷歌公司將以此為基礎構建下一代智能化搜索引擎,知識圖譜技術創造出一種全新的信息檢索模式,為解決信息檢索問題提供了新的思路。本質上,知識圖譜是一種揭示實體之間關系的語義網絡,可以對現實世界的事物及其相互關系進行形式化地描述。現在的知識圖譜已被用來泛指各種大規模的知 識庫。
知識圖譜通常使用三元組的形式來表示,即 G=(E,R,S),其中E={e1,e2,e3,...,en}是知識庫中的實體集合,共包含|E|種不同的實體;R = {r1,r2 ,... ,rn}是知識庫中的關系集合,共包含|R|種不同關系; S?E×R×E代表知識庫中的三元組集合。三元組的基本形式主要包括實體1、關系、實體2和概念、屬性、屬性值等,實體是知識圖譜中的最基本元素,不同的實體間存在不同的關系。概念主要指集合、類別、對象類型、事物的種類,例如人物、地理等; 屬性主要指對象可能具有的屬性、特征、特性、特點以及參數,例如國籍、生日等;屬性值主要指對象指定屬性的值,例如中國、1988-09-08等。每個實體(概念的外延)可用一個全局唯一確定的ID來標識,每個屬性-屬性值對可用來刻畫實體的內在特性,而關系可用來連接兩個實體,刻畫它們之間的關聯。
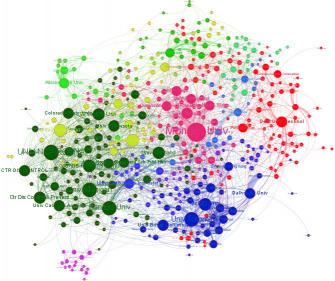
知識圖譜的架構主要包括自身的邏輯結構以及體系架構,目前,大多數知識圖譜都采
用自底向上的方式進行構建,其中最典型就是Google的Knowledge Vaule,知識圖譜體系架構如下圖所示:
隨著語義Web資源數量激增、大量的RDF數據 被發布和共享、LOD等項目的全 展開,學術界與工業界的研究人員花費了大量的精力構建各種結構化的知識庫。這些知識庫大致可以分為兩類:開放鏈接知識庫和行業知識庫。開放鏈接知識庫的典型代表有:Freebase、Wikidata、DBpedia、YAGO;垂直行業知識庫的典型代表有:IMDB(電影數據)、MusicBrainz(音樂數據)、MusicBrainz(語義知識網絡)。
二、 知識圖譜的構建
知識圖譜的構建包括三個步驟:(1)信息抽取:從各種類型的數據源中提取出實體(概念)、屬性以及實體間的相互關系,在此基礎上形成本體化的知識表達;(2)知識融合:在獲 得新知識之后,需要對其進行整合,以消除矛盾和歧義,比如某些實體可能有多種表達,某個特定稱謂也許對應于多個不同的實體等;(3)知識加工:對于經過融合的新知識,需要經過質量評估之后(部分需要人工參與甄別),才能將合格的部分加入到知識庫中, 以確保知識庫的質量。新增數據之后,可以進行知識推理、拓展現有知識、得到新知識。
(1)信息抽取
信息抽取又名知識抽取,是知識圖譜構建的第一步,是一種自動化地從半結構化和無結構數據中抽取實體、關系以及實體屬性等結構化信息的技術,具體分為:實體抽取、關系抽取和屬性抽取。
實體抽取,也稱為命名實體識別,是指從文本數據集中自動識別 出命名實體.實體抽取的質量(準確率和召回率)對后續的知識獲取效率和質量影響極大,因此是信息抽取中最為基礎和關鍵的部分。實體抽取的方法大致可以分為三種:基于規則與詞典的方法、基于統計機器學習的方法以及面向開放域的抽取方法。
關系抽取的目標是解決實體間語義鏈接的問題,早期的關系抽取主要是通過人工構造語義規則以及模板的方法識別實體關系。隨后,實體間的關系模型逐漸替代了人工預定義的語法與規則。關系抽取技術的目的,是解決如何從文本語料中抽取實體間的關系。關系抽取大致可以分為基于開放式實體關系抽取和基于聯合推理的實體關系抽取兩類。
屬性抽取的目標是從不同信息源中采集特定實體的屬性信息。例如針對某個公眾人物,可以從網絡公開信息中得到其昵稱、生日、國籍、教育背景等信息。屬性抽取技術能夠從多種數據來源中匯集這些信息,實現對實體屬性的完整勾畫。由于可以將實體的屬性視為實體與屬性值之間 的一種名詞性關系,因此也可以將屬性抽取問題視為關系抽取問題。
(2)知識融合
通過信息抽取,實現了從非結構化和半結構化數據中獲取實體、關系以及實體屬性信息的目標。然而,這些結果中可能包含大量的冗余和錯誤信息,數據之間的關系也是扁平化的,缺乏層次性和邏輯性,因此有必要對其進行清理和整合。知識融合包括兩部分內容:實體鏈接和知識合并。通過知識融合,可以消除概念的歧義,剔除冗余和錯誤概念,從而確保知識的質量。
實體鏈接是指對于從文本中抽取得到的實體對象,將其鏈接到知識庫中對應的正確實體對象的操作,實體鏈接的一般流程是:1.從文本中通過實體抽取得到實體指稱項;2.進行實體消歧和共指消解,判斷知識庫中的同名實體與之是否代表不同的含義以及知識庫中是否存在其他命名實體與之表示相同的含義;3.在確認知識庫中對應的正確實體對象之后,將該實體指稱項鏈接到知識庫中對應實體。
在構建知識圖譜時,可以從第三方知識庫產品或已有結構化數據獲取知識輸入。例如,關聯開放數據項目會定期發布其經過積累和整理的語義知識數據,其中既包括前文介紹過的通用知識庫 DBpedia和 YAGO,也包括面向特定領域的知識庫產品。知識合并又可分為合并外部知識庫、合并關系數據庫兩個層面。
(3)知識加工
通過信息抽取,可以從原始語料中提取出實體、關系與屬性等知識要素。再經過知識融合,可以消除實體指稱項與實體對象之間的歧義,得到一系列基本的事實表達。然而,事實本身并不等于知識,要想最終獲得結構化、網絡化的知識體系,還需要經歷知 識加工的過程。知識加工主要包括三方面內容:本體構建、知識推理和質量評估。
本體是同一領域內不同主體之間進行交流、連通的語義基礎,其主要呈現樹狀結構,相鄰的層次節點或概念之間具有嚴格的“IsA”關系,有利于進行約束、推理等,卻不利于表達概念的多樣性。本體可通過人工編輯的方式手動構建,也可通 過數據驅動自動構建,然后再經質量評估方法與人工審核相結合的方式加以修正與確認。
知識推理是指從知識庫中已有的實體關系數據出發,經過計算機推理,建立實體間的新關聯,從而拓展和豐富知識網絡。知識推理是知識圖譜構建的重要手段和關鍵環節,通過知識推理,能夠從現有知識中發現新的知識。例如已知(乾隆,父親,雍正)和 (雍正,父親,康熙),可以得到(乾隆,祖父,康熙)或(康熙,孫子,乾隆)。知識推理的對象并不局限于實體間的關系,也可以是實體的屬性值、本體的概念層次關系等。例如已知某實體的生日屬性,可以通過推理得到該實體的年齡屬性。根據本體庫中的概念繼承關系,也可以進行概念推理,例如已知(老虎,科, 貓科)和(貓科,目,食肉目),可以推出(老虎,目,食 肉目)。
質量評估也是知識庫構技術的重要組成部分受現有技術水平的限制,采用開放域信息抽取 技術得到的知識元素有可能存在錯誤(如實體識別 錯誤、關系抽取錯誤等),經過知識推理得到的知識的質量同樣也是沒有保障的,因此在將其加入知識庫之前,需要有一個質量評估的過程;隨著開放關聯數據項目的推進,各子項目所產生的知識庫產品間的質量差異也在增大,數據間的沖突日益增多,如何對其質量進行評估,對于全局知識圖譜的構建起著重要的作用。引入質量評估的意義在于:可以對知識的可信度進行量化,通過舍棄置信度較低的知識,可以保障知識庫的質量。
三、 知識圖譜的應用
知識圖譜為互聯網上海量、異構、動態的大數據表達、組織、管理以及利用提供了一種更為有效的方式,使得網絡的智能化水平更高,更加接近于人類的認知思維。目前,知識圖譜已在智能搜索、深度問答、社交網絡以及一些垂直行業中有所應用,成為支撐這些應用發展的動力源泉。
基于知識圖譜的智能搜索是一種基于長尾的搜索,搜索引擎以知識卡片的形式將搜索結果展現出來。用戶的查詢請求將經過查詢式語義理解與知識檢索兩個方面。具體應用國外的搜索引擎以谷歌的Google Search、微軟的Bing Search]最為典型;而國內國內的主流搜索引擎公司,如百度、搜狗等在近兩年來相繼將知識圖譜的相關研究從概念轉向產品應用。
問答系統是信息檢索系統的一種高級形式,能夠以準確簡潔的自然語言為用戶提供問題的解答。之所以說問答是一種高級形式的檢索,是因為在問答系統中同樣有查詢式理解與知識檢索這兩個重要的過程,并且與智能搜索中相應過程中的相關細節是完全一致的。目前很多問答平臺引入了知識圖譜,國內百度公司研發的小度機器人,天津聚問網絡技術服務中心 開發的大型在線問答系統OASK,專門為門戶、 企業、媒體、教育等各類網站提供良好的交互式問答解決方案。
社交網站 Facebook于2013 年推出了Graph Search產品,其核心技術就是通過知識圖譜將人、地點、事情等聯系在一起,并以直觀的方式支持精確的自然語言查詢,例如輸入查詢式:“我朋友喜歡的餐廳”“住在紐約并且喜歡籃球和中國電影的朋友”等,知識圖譜會幫助用戶在龐大的社交網絡中 找到與自己最具相關性的人、照片、地點和興趣等。Graph Search提供的上述服務貼近個人的生活,滿足了用戶發現知識以及尋找最具相關性的人的需求。
垂直行業的應用以金融、醫療、電商領域為代表,塑造出了金融反欺詐、智能營銷、商品推薦的應用場景。
結束語:
在未來的幾年時間內,知識圖譜毫無疑問將是人工智能的前沿研究問題。知識圖譜的重要性不僅在于它是一個全局知識庫,更是支撐智能搜索和深度問答等智能應用的基礎,而且在于它是一把鑰匙,能夠打開人類的知識寶庫,為許多相關學科領域開啟新的發展機會。從這個意義上來看,知識圖譜不僅是一項技術,更是一項戰略資產。
【參考文獻】:
【1】劉嶠, 李楊, 段宏,等. 知識圖譜構建技術綜述[J]. 計算機研究與發展, 2016, 53(3):582-600.
【2】徐增林, 盛泳潘, 賀麗榮,等. 知識圖譜技術綜述[J]. 電子科技大學學報, 2016, 45(4):589-606.
對深度學習感興趣,熱愛Tensorflow的小伙伴,歡迎關注我們的網站http://www.panchuang.net 我們的公眾號:磐創AI。

張夕華